本次实训的需求为颐养中心。需求书和任务书的具体内容就不再赘述。
本篇文章的主要内容:如何在满足需求的基础下提高程序的可用性,核心功能的实现原理分析与具体代码,反思与总结。
把自己的思路整理并分享,于我,是一种享受,亦是一种反思、提升。
众所周知,实训要求使用 Java 的 JavaFX 或 Swing 实现。不允许使用 Web 开发、不允许使用数据库。
对于许多大牛而言,Vue 早已盛行,Electron 横扫客户端,Go 渗入后端。这些语言、框架早已替代 JavaFX。
但是,有限且落后的语言,并不能阻止学习的步伐。决定一个程序员的上限的,不是程序员所使用的语言所决定的。
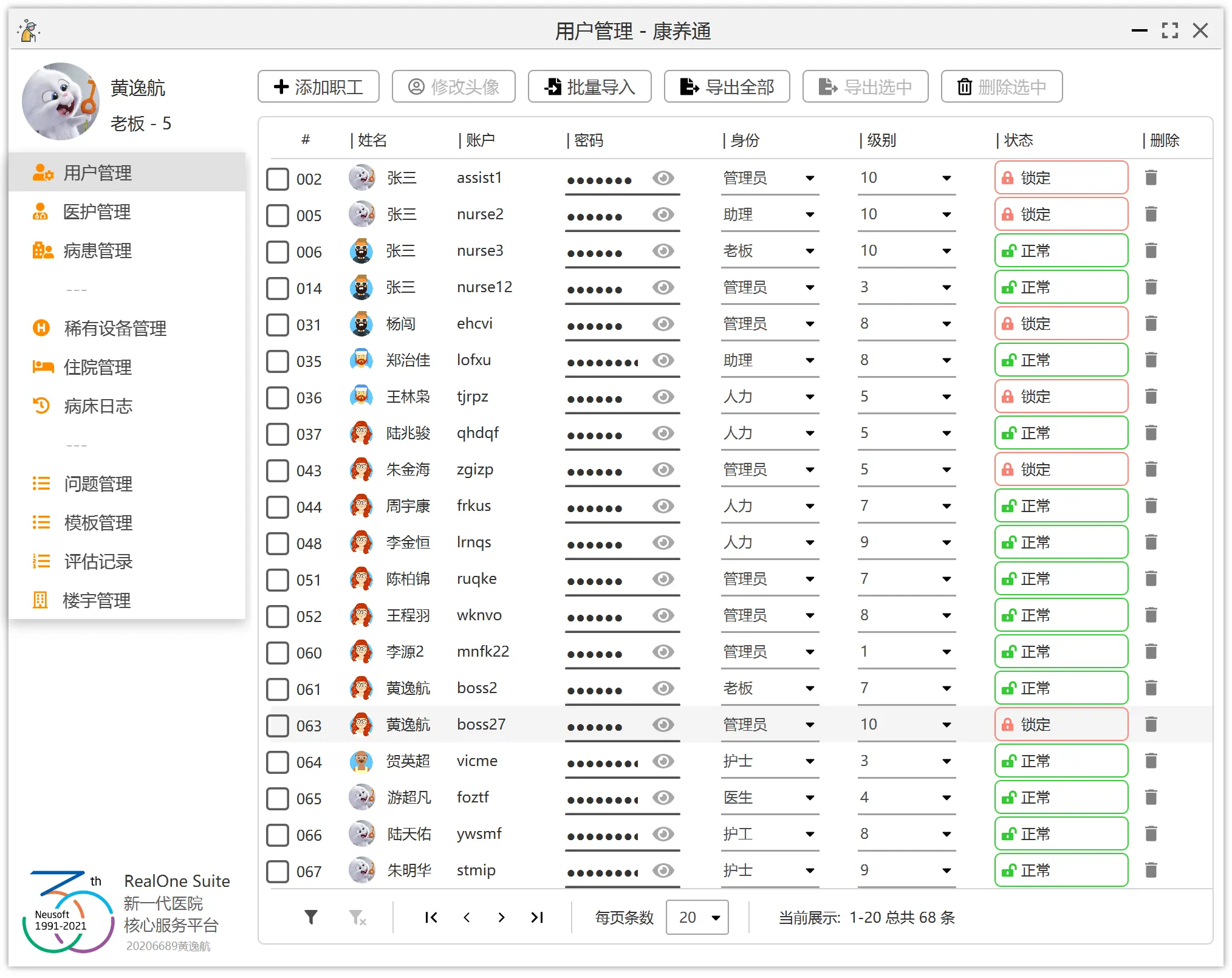
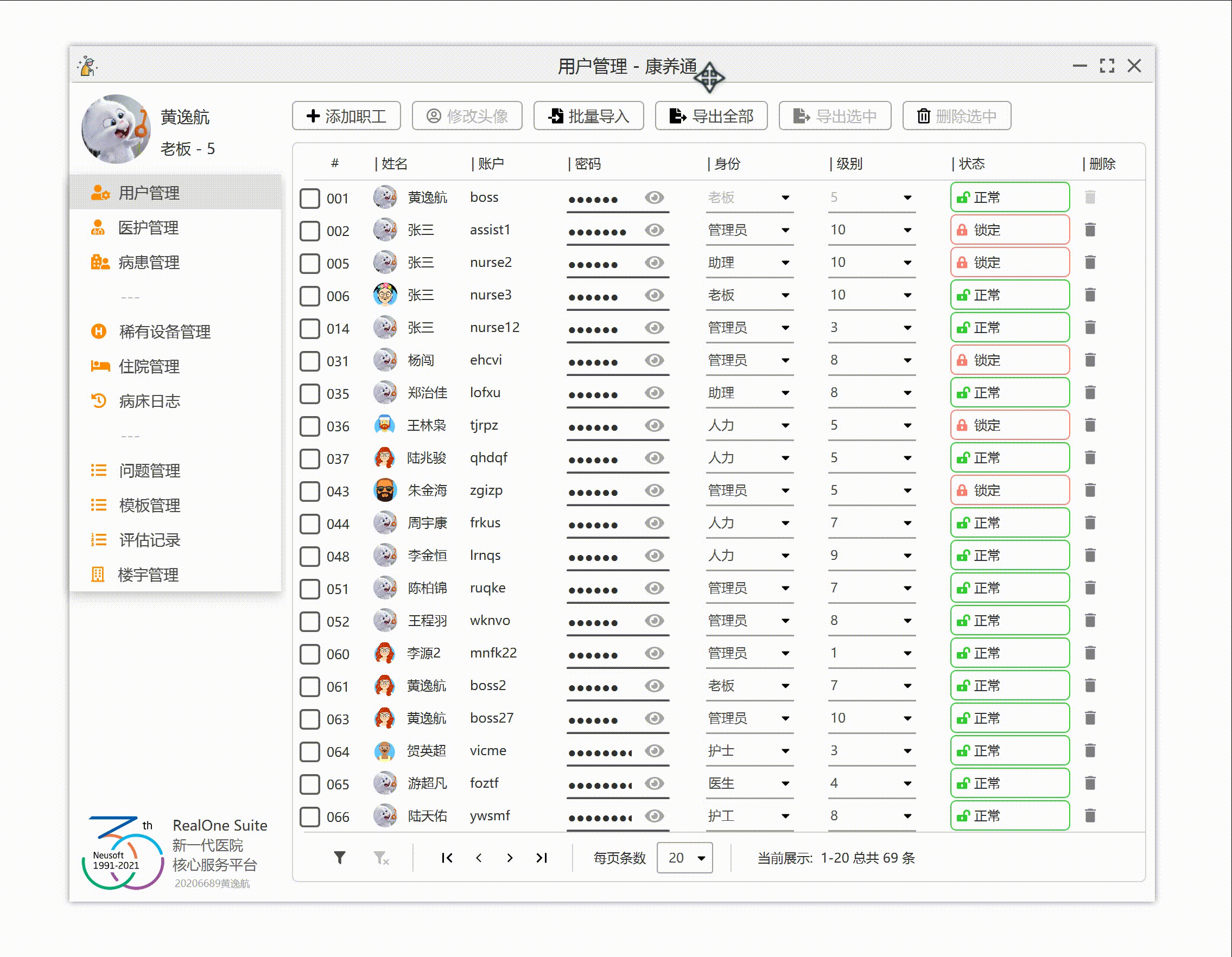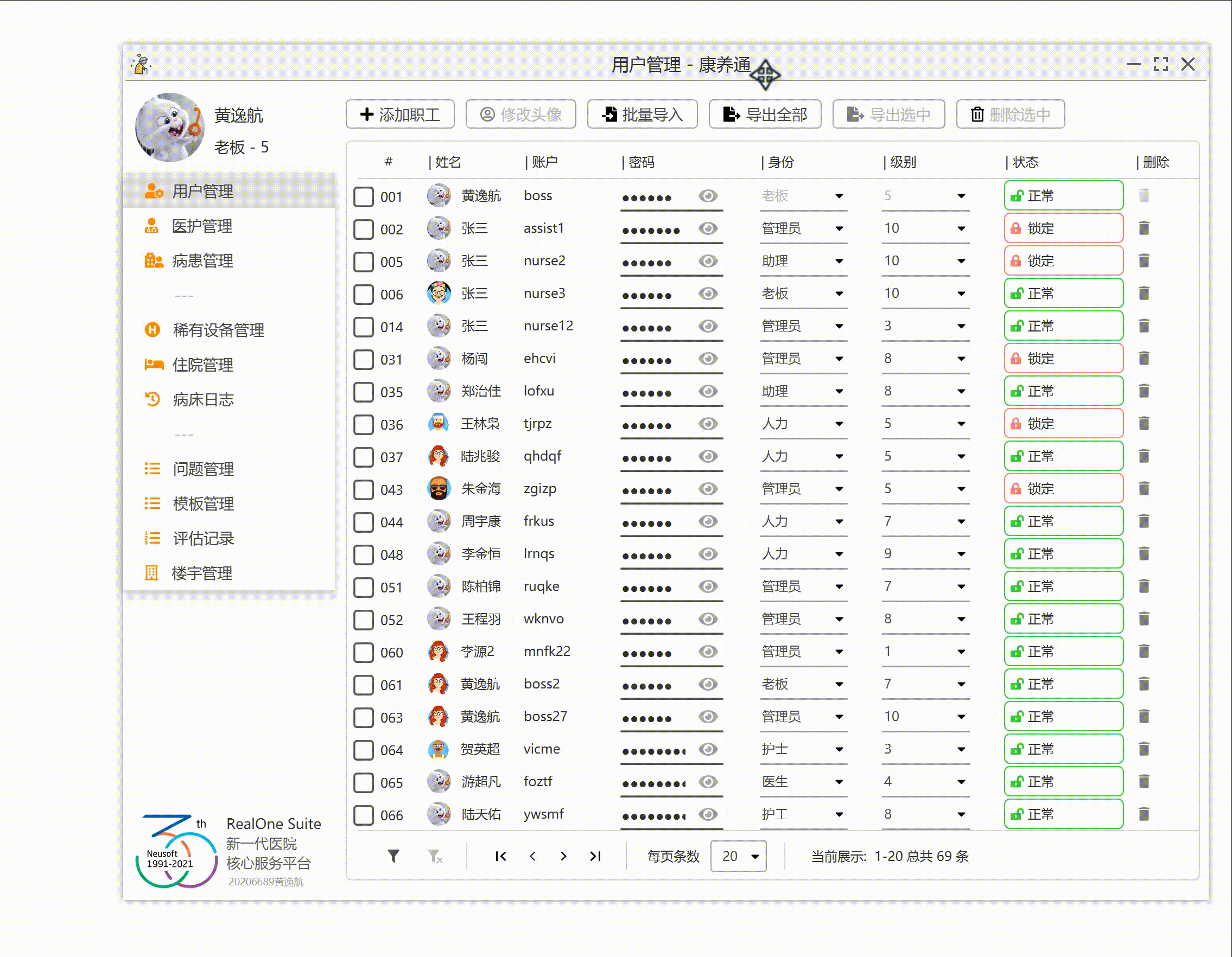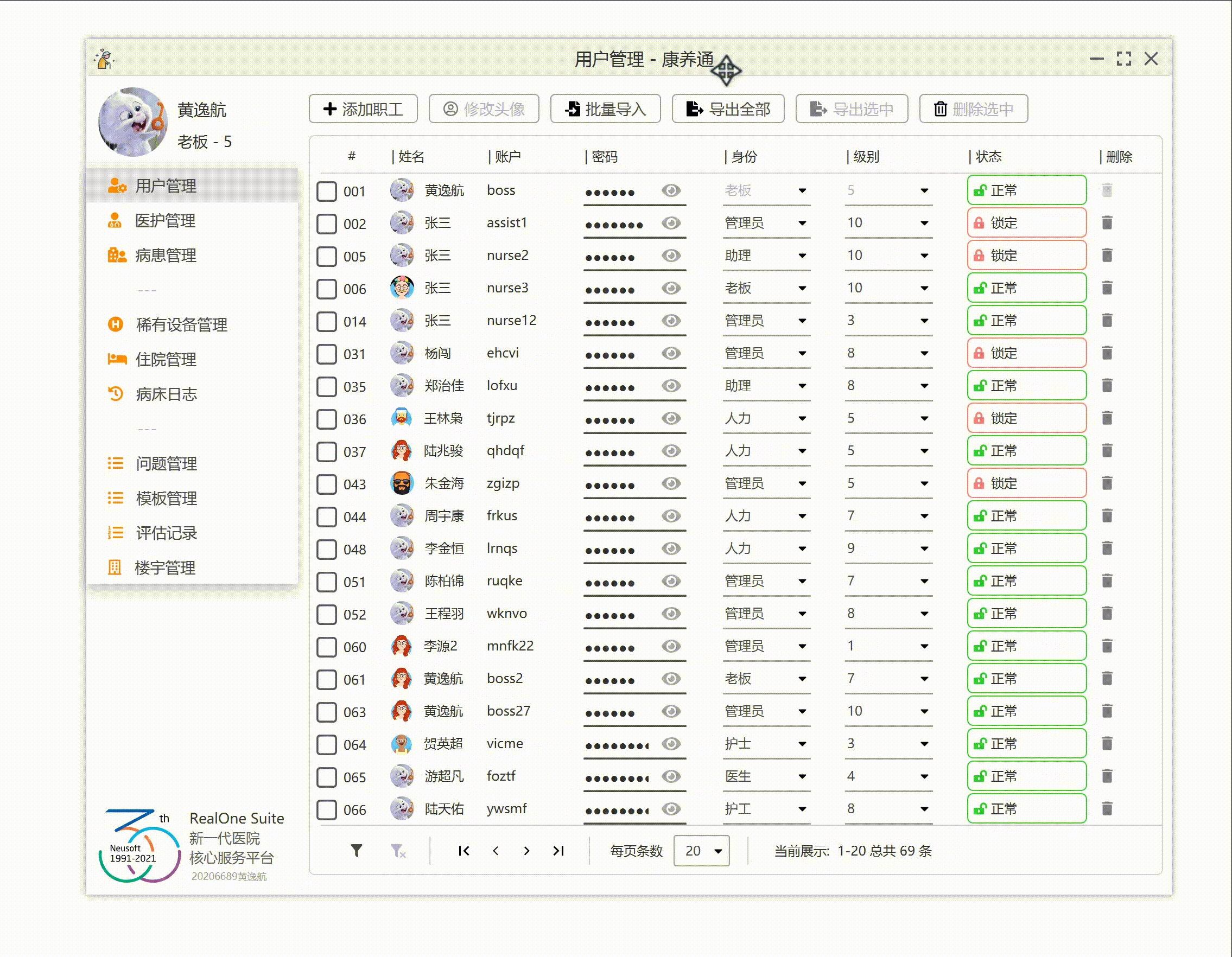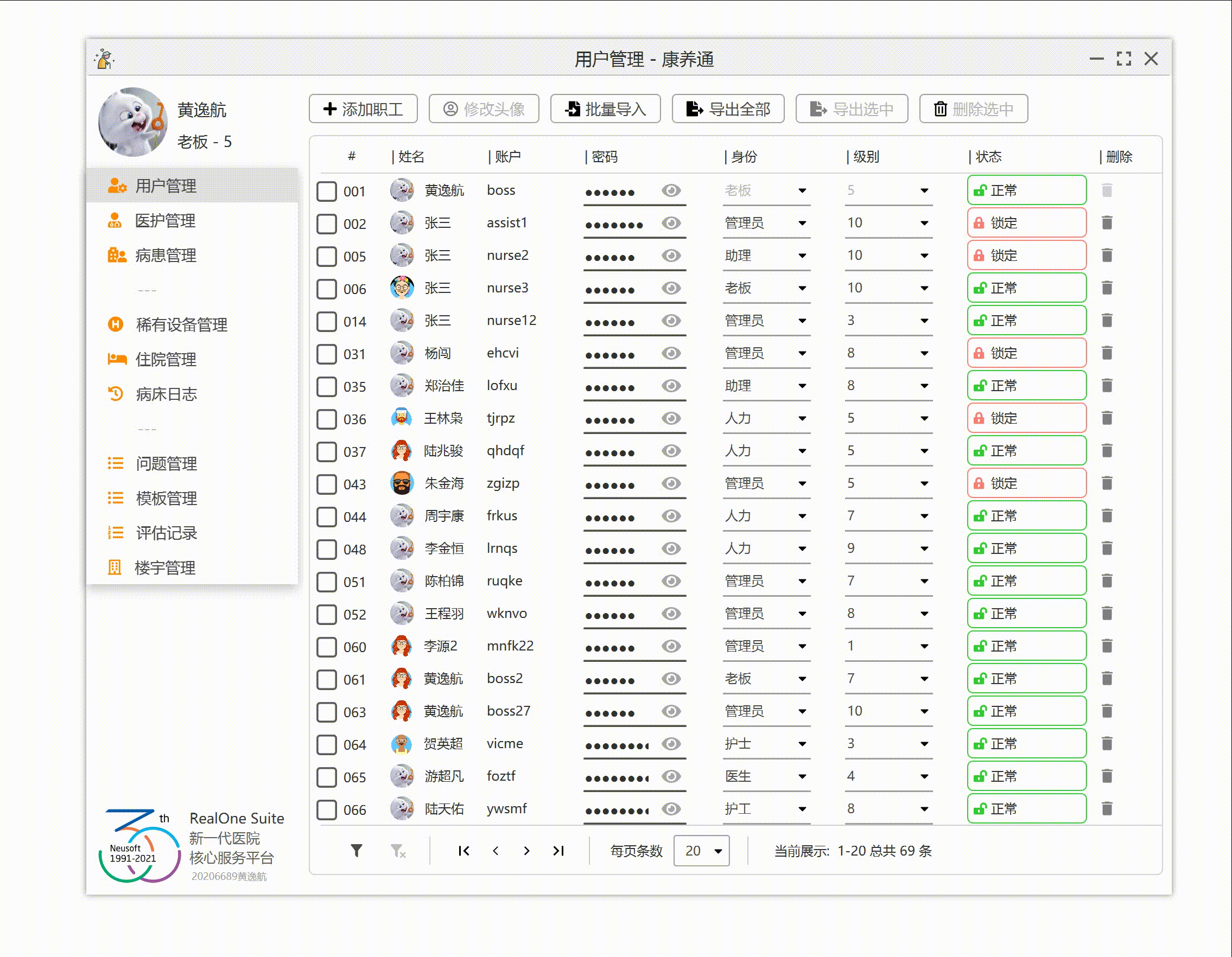
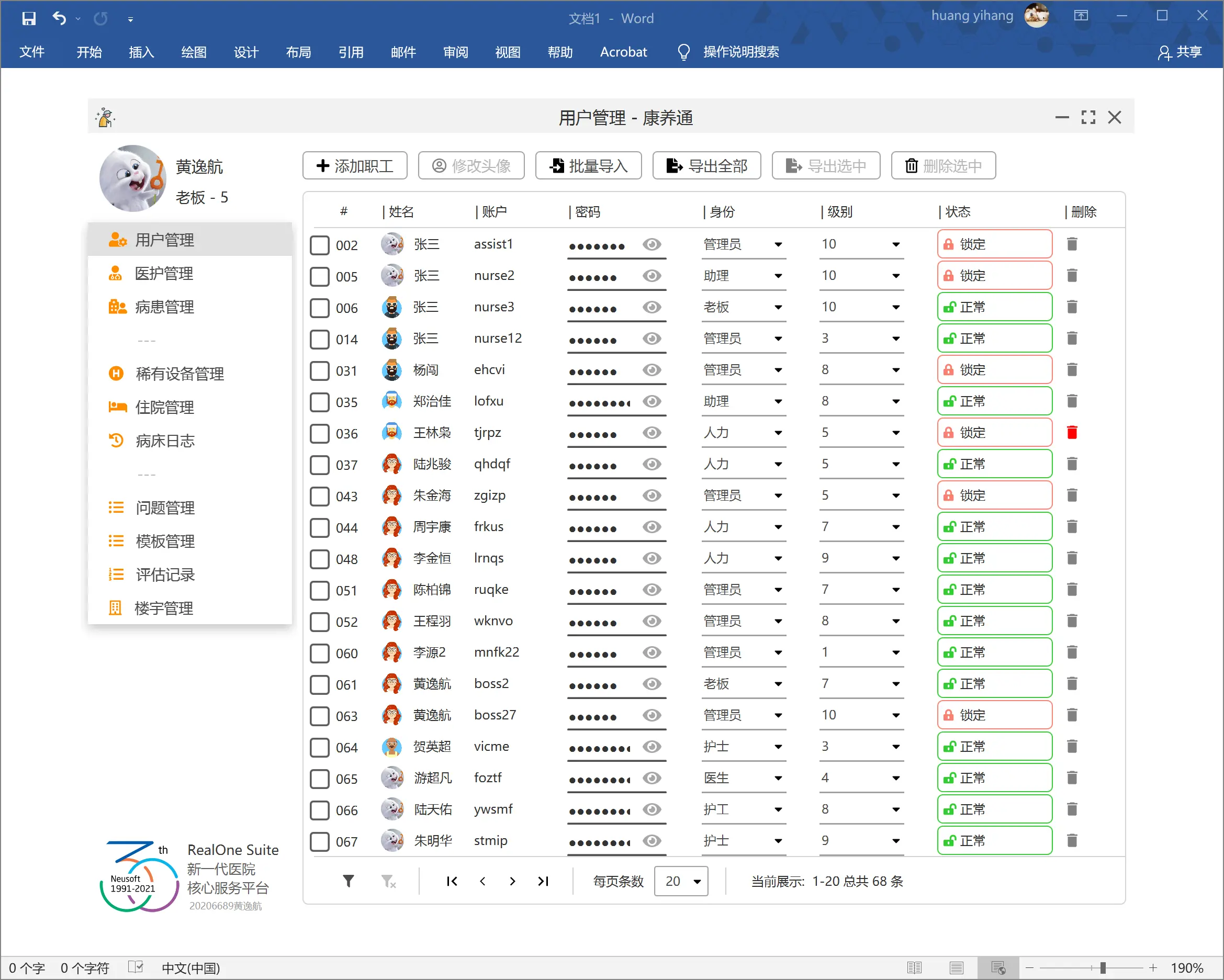
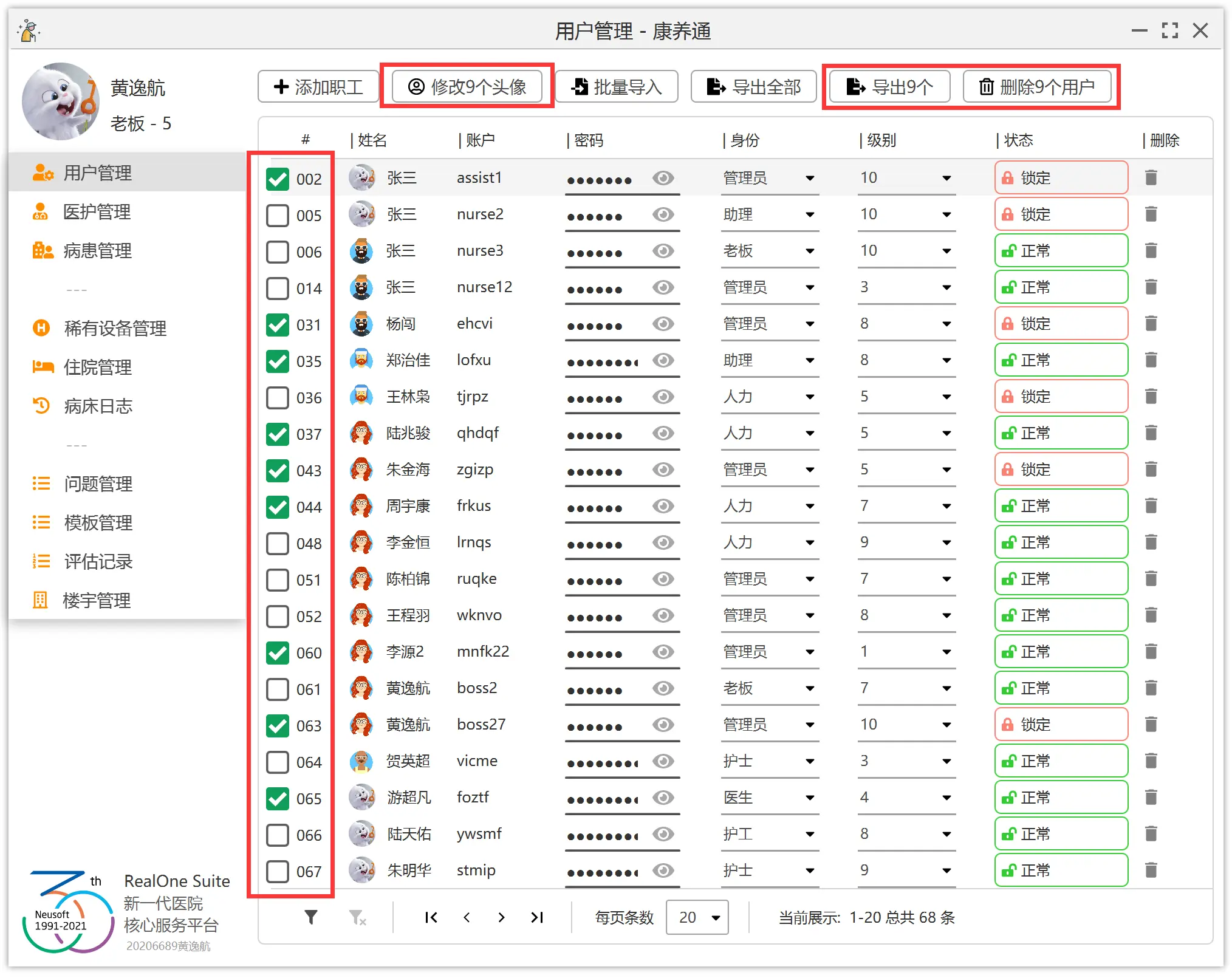
左侧个人信息栏和菜单栏。用于显示具有权限的菜单和个人信息。
右侧为主区域,上方放置操作按钮,下方放置列表。
左下方放置当前应用程序的基础信息。
上方为标题栏。标题栏居中放置标题,左侧放置 logo,右侧放置窗口按钮。
这里的布局,没有使用第三方库。(因为我看了下第三方库自带的窗口样式,都不符合本次需求的主题)
我们只需要使用以下代码,即可隐藏 JavaFX 默认的窗口样式。
1 this .primaryStage.initStyle(StageStyle.TRANSPARENT);
但是,问题随之而来。隐藏默认的窗口样式后,会使得标题栏和边框及边框阴影消失。
即:关闭、最小化、标题都会消失,窗口没有阴影会显得与其他应用程序融为一体。
那么,我们就来解决这些问题。
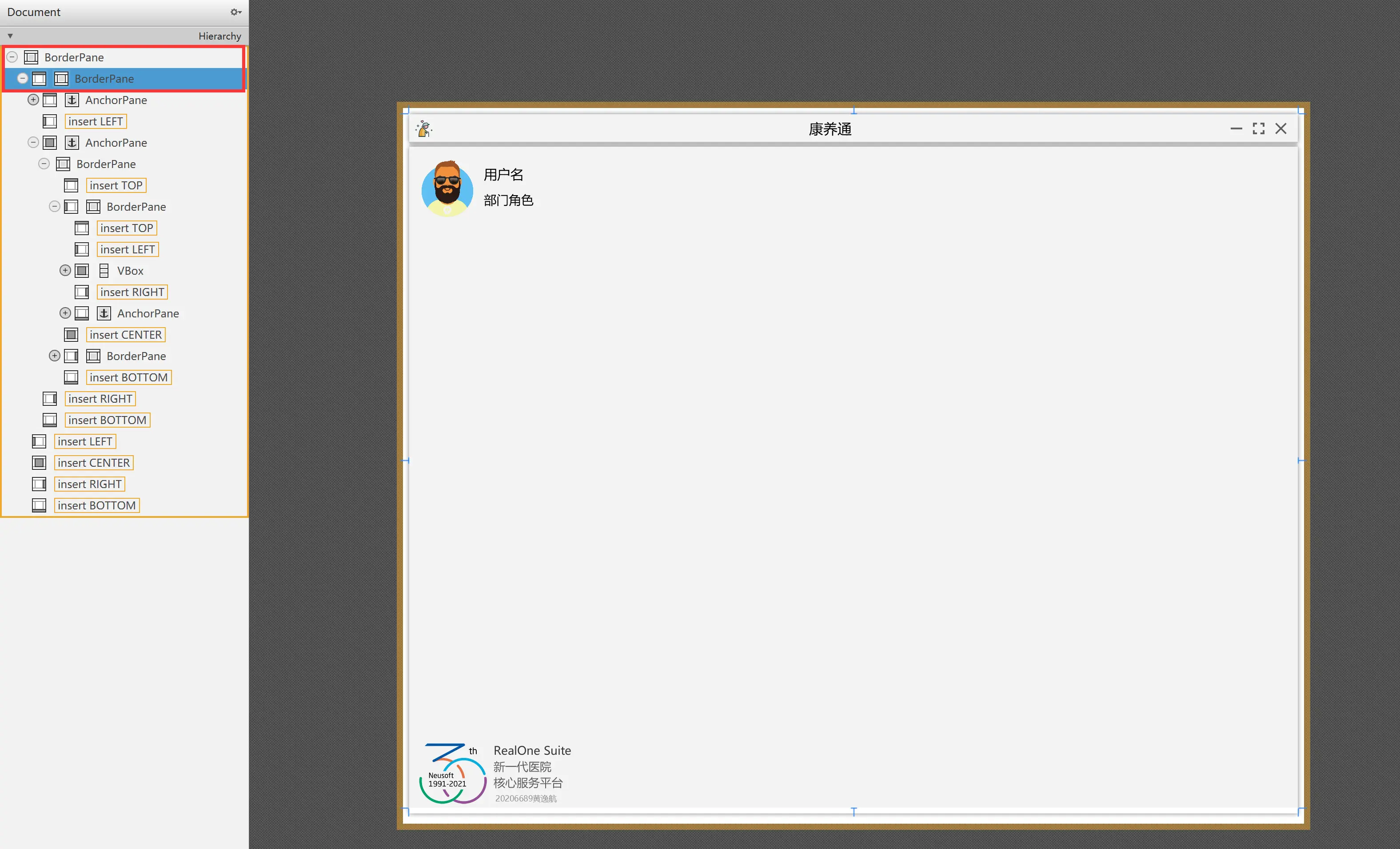
标题栏就需要自己画一个。只需要利用 Scene Builder 和 BorderPane 即可轻松画出标题栏。
接下来,我们要实现事件响应,即关闭等按钮和窗口拖拽事件响应。
主要难点在实现窗口拖拽上。
因为这里涉及到复杂的坐标计算,我直接给出最终的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package com.pension.utils.windowDrag; import javafx.event .EventHandler; import javafx.scene.Node; import javafx.scene.input.MouseEvent; import javafx.stage.Stage; public class DragListener implements EventHandler <MouseEvent > { private double xOffset = 0 ; private double yOffset = 0 ; private final Stage stage; public DragListener (Stage stage ) this .stage = stage; } @Override public void handle (MouseEvent event ) event .consume(); if (event .getEventType() == MouseEvent.MOUSE_PRESSED) { xOffset = event .getSceneX(); yOffset = event .getSceneY(); System.out .println(xOffset + " " + yOffset); } else if (event .getEventType() == MouseEvent.MOUSE_DRAGGED) { stage.setX(event .getScreenX() - xOffset); if (event .getScreenY() - yOffset < 0 ) { stage.setY(0 ); }else { stage.setY(event .getScreenY() - yOffset); } } } public void enableDrag (Node node ) node.setOnMousePressed(this ); node.setOnMouseDragged(this ); } }
1 2 3 4 5 6 7 8 9 10 package com.pension.utils.windowDrag;import javafx.scene.Node;import javafx.stage.Stage;public class DragUtil public static void addDragListener (Stage stage, Node root) new DragListener(stage).enableDrag(root); } }
引入以上两个类到 Util 中,然后使用以下代码给节点绑定事件。
1 2 3 DragUtil.addDragListener (primaryStage, controller.top );
如果不实现窗口阴影,就是下面这种效果。没有窗口阴影会使得应用程序之间的分界不明显。
下面是加了窗口阴影后的效果。
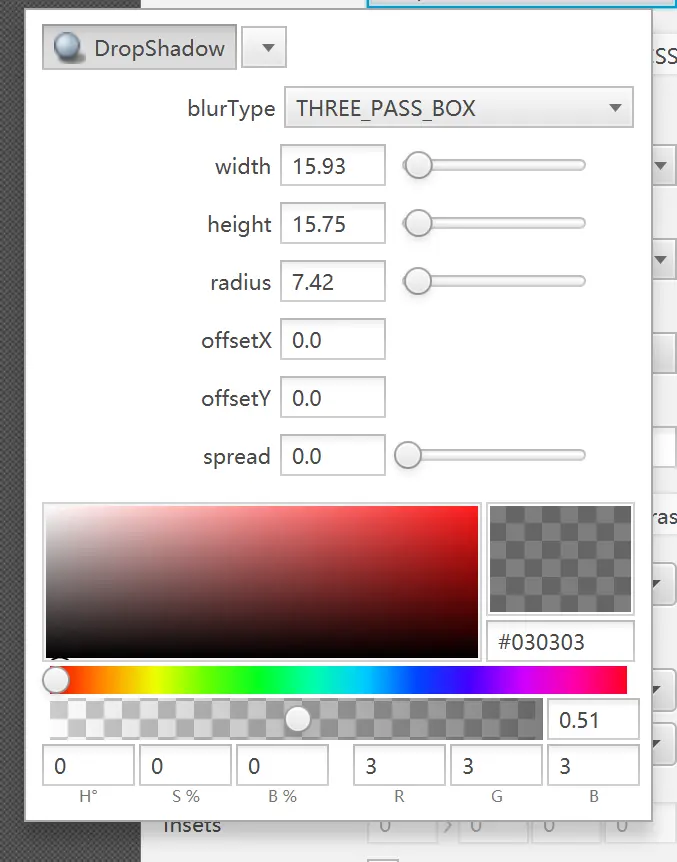
经过大量尝试,没有一种方法可以直接实现原生的窗口阴影效果。因为,无论使用哪一种 Effect 效果,都只能使得阴影在节点的内部出现。要注意的是,我们这里要添加的阴影节点是最外层的节点。Dropshadow 可以实现在某个节点的外部添加阴影。但是,如果该节点(A)不存在父节点(B),那么给节点 A 添加 Dropshadow 会导致此阴影无法显示。
那么,既然不能给不存在父节点的子节点添加 Dropshadow 效果,我们就使用如下思路实现窗口阴影。
将我们的根面板(根面板指包含标题栏在内的用于显示应用程序全部内容的面板)整体移入至一个新面板中,使得根面板成为新面板的子节点。如下图所示,第一个 BorderPane 是新面板,第二个则是我们的根面板。为了使得阴影可以被显示出来,我们让根面板的大小比新面板要小一些。也就是说,给根面板添加 Padding,使得四条边与新面板的边界都保持一定的距离。
完成以上步骤后,我们设置新面板的背景为 Transparent。给根面板设置 Effect 效果。这里的 Effect 效果,是模仿 QQ 聊天界面窗口的阴影。具体的参数可以自行设定,但我个人感觉 QQ 聊天窗口的阴影比较舒适。
至此,我们就实现了自定义窗口的阴影效果。
基础的增删改查功能不做赘述。
最终完成效果如下。
有些小伙伴利用第三方组件或库不用动手就能实现批量操作。
这里,我们只是利用第三方库来美化组件的样式(也就是你看到的比较漂亮的勾选框和按钮样式)。下面将会讲解批量操作的实现原理。
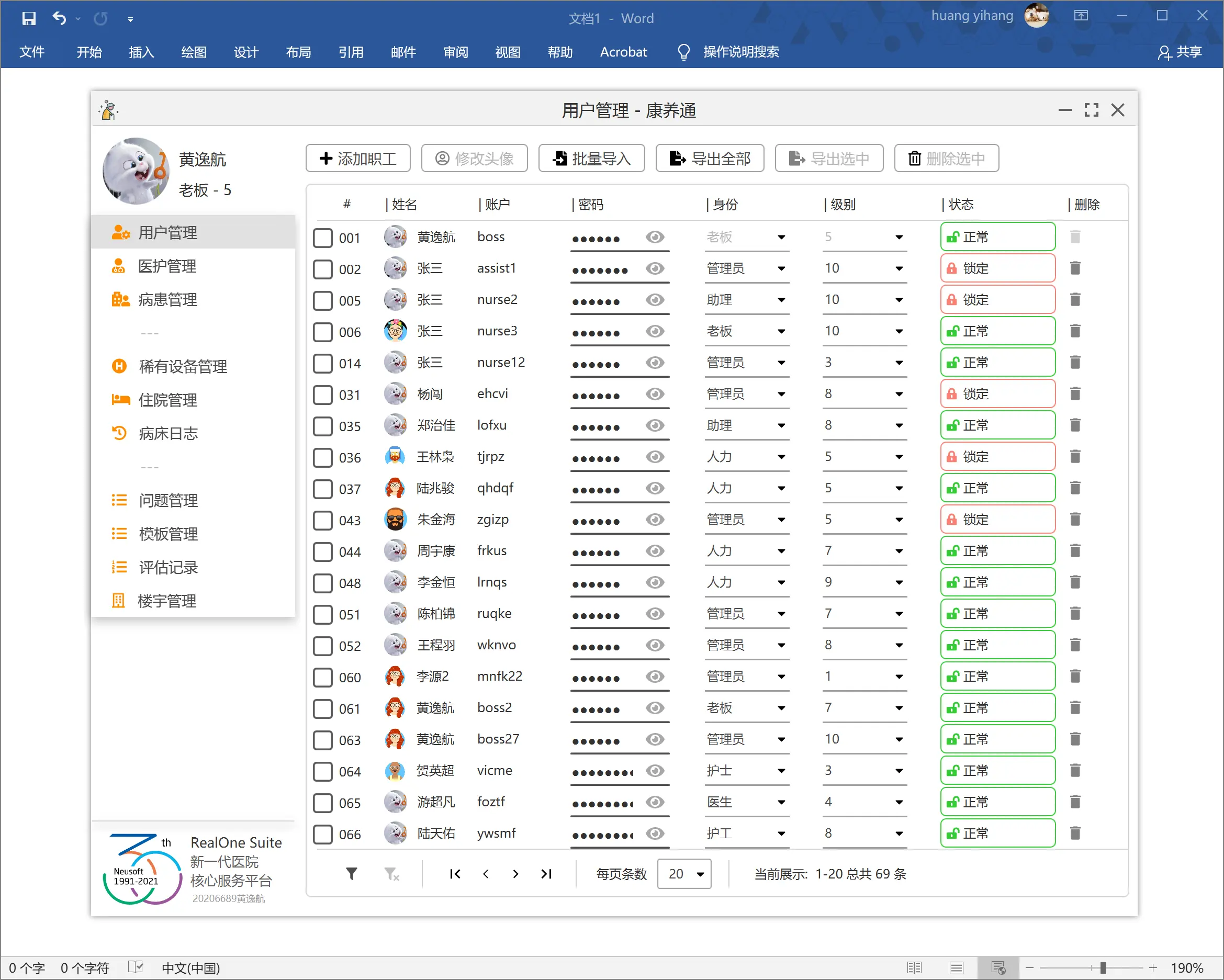
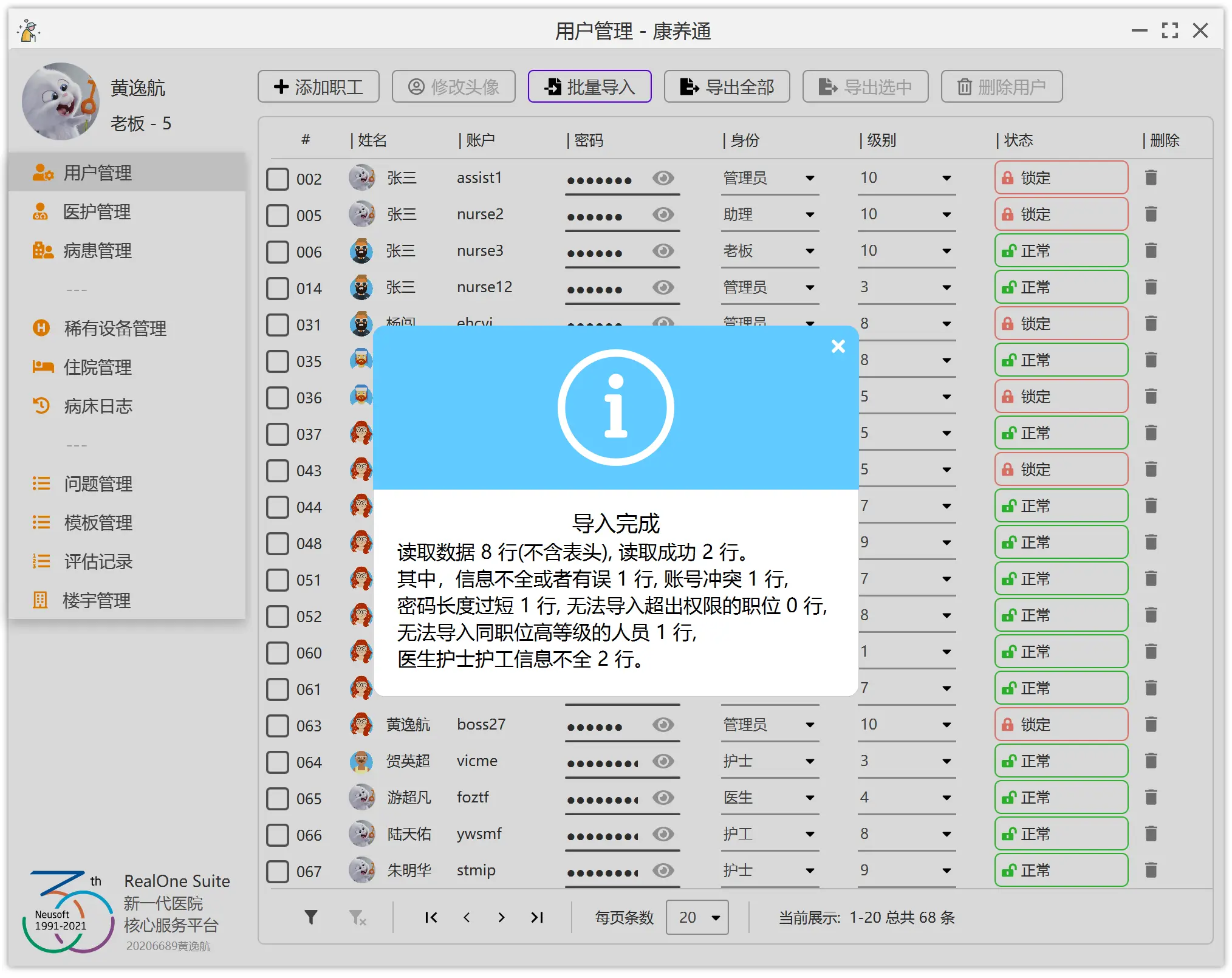
最初的实现方案是:在构造表格时,给每一行的第一列添加上勾选框。并且给每一个勾选框都添加上监听事件,如果该勾选框被勾选,则标记对应的用户。
显然,这有一个非常致命的缺陷,也就是,如果我们进行了翻页等操作,导致表格被重新渲染(也就是重新构造了整个表格),那么勾选的状态将会丢失。也就是,上面那一种方案,我们只是将勾选框单向地与每一个用户进行了关联。如果我们选中了第一页的 3 个用户,然后将表格翻页至第二页,(第二页不做任何操作)再翻回第一页,那么前面 3 个用户的勾选状态将会丢失。显然,这不符合一般程序的设计规范。
那么,我们将此方案进行修改。
在这一个系统中,每一个用户都是 Person 实体类的对象。我们给 Person 类添加一个属性,这一个属性就是一个勾选框。那么,刚刚的问题就非常好解决。不难发现,我们这样其实是将勾选框和人双向绑定在了一起。无论表格被翻到哪一页,每一个用户的勾选状态都像其他用户属性一样,始终跟随着用户。
如果用户点击了批量操作的按钮,比如批量修改或者批量删除的按钮,那么程序只需要遍历全部的用户,检查每一个用户的勾选状态,即可判定使用者是否勾选了该用户。
头像裁剪功能随处可见,微信 QQ 上传头像都会提示裁剪头像。
JavaFX 虽然是老古董,但是实现头像裁剪(也就是实现图像裁剪,头像裁剪只不过是 1:1 裁剪)并非不可行。
不难发现,其实只需要处理两个组件,第一个是底部的原始图片,第二个是可以拖拽移动的矩形。
加载原始图片的时候,需要注意:用户选择的图片是否过小过大,如果是,则需要对图片进行合适的缩放,以保证图片的显示效果。如果需要进行缩放,那么还要考虑到一个问题,用户的图片是否存在图片长宽比异常的问题。设想一下,我的裁剪图像的窗口只有 512x512,如果用户上传了一张 1x10000 的图片(以极端情况举例更好理解,前者为宽),如果你将宽度缩放至 512,那么为了不让图片变形,你就需要将长度缩放至 10000 的 512 倍。显然,这张图片会超出我们的显示窗口。因此,我们的程序要处理好这一类图片的缩放问题,而不能简单除暴地按照长或者宽进行缩放。但无论如何,只有两个缩放方法,要么按照长度缩放,要么按照宽度缩放(按照长度缩放,也就是说,将图片长度缩放到指定像素,而宽度跟随长度改变。)。因此,我们只需要计算两种方法缩放后的图片大小,然后进行判断并选择合适的缩放方法即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 double maxWidth = 512 ; double maxHeight = 512 ; double minWidth = 200 ; double minHeight = 200 ; double finalWidth = 0 ; double finalHeight = 0 ; if (image.getHeight () >= maxHeight && image.getWidth () >= maxWidth) { System.out.println ("进行缩放" ); double resizeWidth = image.getWidth () * maxHeight / image.getHeight (); System.out.println ("按照最大高度进行缩放 width = " + resizeWidth + ", height = " + maxHeight); double resizeHeight = image.getHeight () * maxWidth / image.getWidth (); System.out.println ("按照最大宽度进行缩放 width = " + maxWidth + ", height = " + resizeHeight); if (resizeWidth >= maxWidth) { finalHeight = resizeHeight; finalWidth = maxWidth; } else { finalHeight = maxHeight; finalWidth = resizeWidth; } } else { finalHeight = image.getHeight (); finalWidth = image.getWidth (); }
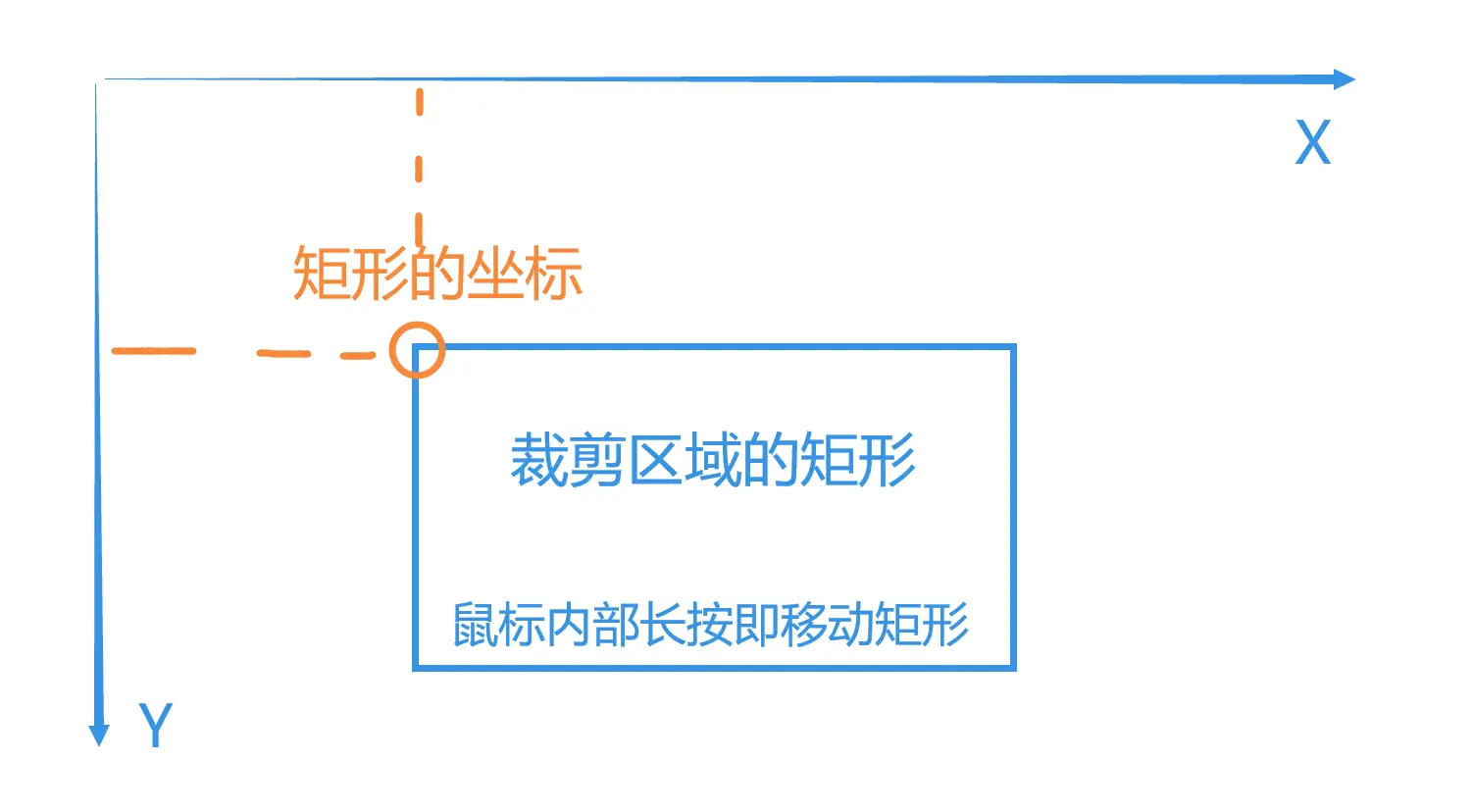
众所周知,JavaFX 画出一个矩形,同时需要两个参数,第一个参数是矩形左上角那个点的坐标,以及矩形的大小(长和宽)。
知道了这一点,我们就可以实现拖拽改变矩形大小。
当用户点击(鼠标长按的第一下也记为点击操作)时,获取用户的鼠标位置(坐标 A) ,并记录。
注意:坐标 A 并不一定是矩形的左上角的坐标。因为,如果用户是向左上角拖拽的,那么坐标 A 是矩形右下角的坐标。同理,向右上角拖拽时,坐标 A 是矩形左下角的坐标。
当用户开始拖拽时,获取用户的鼠标坐标 (坐标 B),并记录。
我们可以通过坐标 A 和坐标 B 的相对位置关系,计算出矩形的实际大小和矩形的左上角坐标,并绘制矩形。
需要注意的是,这里使用的坐标轴,X 轴是水平方向,方向向右。Y 轴是垂直方向,方向向下。
还需要注意的是,A 和 B 的坐标差并不是最终的矩形大小。因为我们要实现正方形裁剪,但是 A 和 B 的坐标差并不始终为 1:1。那么,我们这里采取的方案是:如果用户的鼠标拖拽出来的区域大小为 200x250(假设),那么我们就认为用户拖拽出来的大小为 200x200。即:始终取两者的最小值。当然,你也可以始终取最大值,但这与一般逻辑不相符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 double offsetX = event.getX() - dragContext.mouseAnchorX; double offsetY = event.getY() - dragContext.mouseAnchorY; if (offsetY >= 0 && offsetX >= 0 ) { rect .setWidth(Math .min(offsetX, offsetY)); rect .setHeight(Math .min(offsetX, offsetY)); } if (offsetY < 0 && offsetX < 0 ) { rect .setWidth(Math .min(offsetX * (-1.0 ), offsetY * (-1 ))); rect .setHeight(Math .min(offsetX * (-1.0 ), offsetY * (-1 ))); rect .setX(ImageCrop.clickX - Math .min(offsetX * (-1.0 ), offsetY * (-1 ))); rect .setY(ImageCrop.clickY - Math .min(offsetX * (-1.0 ), offsetY * (-1 ))); } if (offsetY >= 0 && offsetX < 0 ) { rect .setWidth(Math .min(offsetX * (-1 ), offsetY)); rect .setHeight(Math .min(offsetX * (-1 ), offsetY)); rect .setX(ImageCrop.clickX - Math .min(offsetX * (-1 ), offsetY)); } if (offsetY < 0 && offsetX >= 0 ) { rect .setWidth(Math .min(offsetX, offsetY * (-1 ))); rect .setHeight(Math .min(offsetX, offsetY * (-1 ))); rect .setY(ImageCrop.clickY - Math .min(offsetX, offsetY * (-1 ))); }
接下来,我们要实现拖拽移动矩形。实现的思路非常简单,如果用户是在矩形内的长按,那么就触发移动矩形的事件。
在用户点击(鼠标长按的第一下也记为点击操作)时,计算这一次点击事件的坐标 A 与矩形的左上角的坐标 B 的差。我们需要保存这一个差值(X 的坐标差和 Y 的坐标差)。显然,这一个差值,X 和 Y 都肯定是 >0 的,因为点击的位置一定是在矩形内的,也就是一定是在矩形左上角的右下方。
当用户开始拖拽时,获取当前的鼠标位置。利用刚刚保存的坐标差和当前鼠标的坐标来计算矩形的左上角坐标。计算出后,更新矩形的左上角坐标,即可实现拖拽移动。
通过以上的思路,即可实现拖拽生成 1:1 大小的矩形和长按移动。
这里的难点,主要是要充分理解各种鼠标事件的触发的先后顺序,以及计算各种坐标。
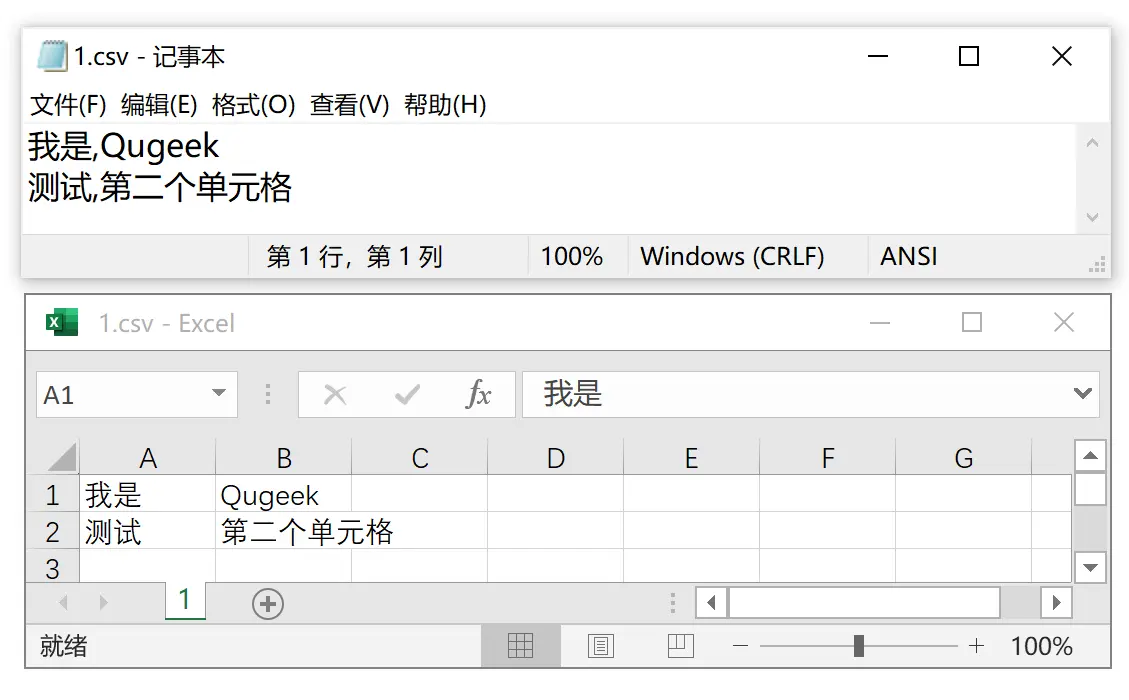
批量导出,实现比较简单。批量导出的文件格式为 CSV 格式。CSV 其实是一种以逗号为分隔符的 TXT 文件。如果你尝试将你的一个 TXT 文件的内容修改为"1,2"(不包括引号),然后将文件后缀名修改为 csv。然后双击这个文件,你会发现 Excel 能够打开这样的文件。
也就是说,我们只要按照这个格式生成 csv 文件,就能实现批量导出信息到 Excel 文件中。
但是,难点在于,从 Excel 文件中批量导入信息到应用程序中。因为,我们平时使用的 Excel 都是默认 xlsx 或者 xls 格式。我们不能指望使用者先将 Excel 文件转成 csv 文件后,再在程序中批量导入。为了提供体验度,我们应该直接适配 xlsx 等 Excel 文件格式。
这里,为了方便读取 Excel 中的每一个单元格,我们使用第三方库:poi-ooxml-4.1。
然后引入下面这一个工具类。这一个工具类可以帮助我们读取 Excel 中的每一个单元格。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 package com.pension;import java.io.File;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStream;import java.text.SimpleDateFormat;import java.util.ArrayList;import org.apache.poi.hssf.usermodel.HSSFFormulaEvaluator;import org.apache.poi.hssf.usermodel.HSSFWorkbook;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.DateUtil;import org.apache.poi.ss.usermodel.FormulaEvaluator;import org.apache.poi.ss.usermodel.Row;import org.apache.poi.ss.usermodel.Sheet;import org.apache.poi.ss.usermodel.Workbook;import org.apache.poi.xssf.usermodel.XSSFFormulaEvaluator;import org.apache.poi.xssf.usermodel.XSSFWorkbook;public class ExcelUtil { @SuppressWarnings({ "unused" }) public static ArrayList<ArrayList<String>> excelReader (String excelPath,int ... args) throws IOException { Workbook workbook = null ; FormulaEvaluator formulaEvaluator = null ; File excelFile = new File (excelPath); InputStream is = new FileInputStream (excelFile); if (excelFile.getName().endsWith("xlsx" )) { workbook = new XSSFWorkbook (is); formulaEvaluator = new XSSFFormulaEvaluator ((XSSFWorkbook) workbook); }else { workbook = new HSSFWorkbook (is); formulaEvaluator = new HSSFFormulaEvaluator ((HSSFWorkbook) workbook); } if (workbook == null ){ System.err.println("未读取到内容,请检查路径!" ); return null ; } ArrayList<ArrayList<String>> als = new ArrayList <ArrayList<String>>(); for (int numSheet = 0 ; numSheet < workbook.getNumberOfSheets(); numSheet++) { Sheet sheet = workbook.getSheetAt(numSheet); if (sheet == null ) { continue ; } for (int rowNum = 0 ; rowNum <= sheet.getLastRowNum(); rowNum++) { Row row = sheet.getRow(rowNum); if (row == null ) { continue ; } ArrayList<String> al = new ArrayList <String>(); for (int columnNum = 0 ; columnNum < args.length ; columnNum++){ Cell cell = row.getCell(args[columnNum]); al.add(getValue(cell, formulaEvaluator)); } als.add(al); } } is.close(); return als; } @SuppressWarnings({ "unused" }) public static ArrayList<ArrayList<String>> excelReader (String excelPath) throws IOException { Workbook workbook = null ; FormulaEvaluator formulaEvaluator = null ; File excelFile = new File (excelPath); InputStream is = new FileInputStream (excelFile); if (excelFile.getName().endsWith("xlsx" )) { workbook = new XSSFWorkbook (is); formulaEvaluator = new XSSFFormulaEvaluator ((XSSFWorkbook) workbook); }else { workbook = new HSSFWorkbook (is); formulaEvaluator = new HSSFFormulaEvaluator ((HSSFWorkbook) workbook); } if (workbook == null ){ System.err.println("未读取到内容,请检查路径!" ); return null ; } ArrayList<ArrayList<String>> als = new ArrayList <ArrayList<String>>(); for (int numSheet = 0 ; numSheet < workbook.getNumberOfSheets(); numSheet++) { Sheet sheet = workbook.getSheetAt(numSheet); if (sheet == null ) { continue ; } for (int rowNum = 0 ; rowNum <= sheet.getLastRowNum(); rowNum++) { Row row = sheet.getRow(rowNum); if (row == null ) { continue ; } ArrayList<String> al = new ArrayList <String>(); for (int columnNum = 0 ; columnNum < row.getLastCellNum(); columnNum++){ Cell cell = row.getCell(columnNum); al.add(getValue(cell, formulaEvaluator)); } als.add(al); } } is.close(); return als; } @SuppressWarnings("deprecation") private static String getValue (Cell cell, FormulaEvaluator formulaEvaluator) { if (cell==null ){ return null ; } switch (cell.getCellType()) { case STRING: return cell.getRichStringCellValue().getString(); case NUMERIC: if (DateUtil.isCellDateFormatted(cell)) { short format = cell.getCellStyle().getDataFormat(); SimpleDateFormat sdf = null ; if (format == 14 || format == 31 || format == 57 || format == 58 ){ sdf = new SimpleDateFormat ("yyyy-MM-dd" ); }else if (format == 20 || format == 32 ) { sdf = new SimpleDateFormat ("HH:mm" ); } return sdf.format(cell.getDateCellValue()); } else { double cur = cell.getNumericCellValue(); long longVal = Math.round(cur); Object inputValue = null ; if (Double.parseDouble(longVal + ".0" ) == cur) { inputValue = longVal; } else { inputValue = cur; } return String.valueOf(inputValue); } case BOOLEAN: return String.valueOf(cell.getBooleanCellValue()); case FORMULA: return String.valueOf(formulaEvaluator.evaluate(cell).getNumberValue()); default : return null ; } } }
引入工具类后,只需要通过以下代码,即可获取指定 Excel 文件的全部内容。返回的格式是一个二维字符串集合。
1 ArrayList <ArrayList <String >> arrayLists = ExcelUtil.excelReader (file.getAbsolutePath ());
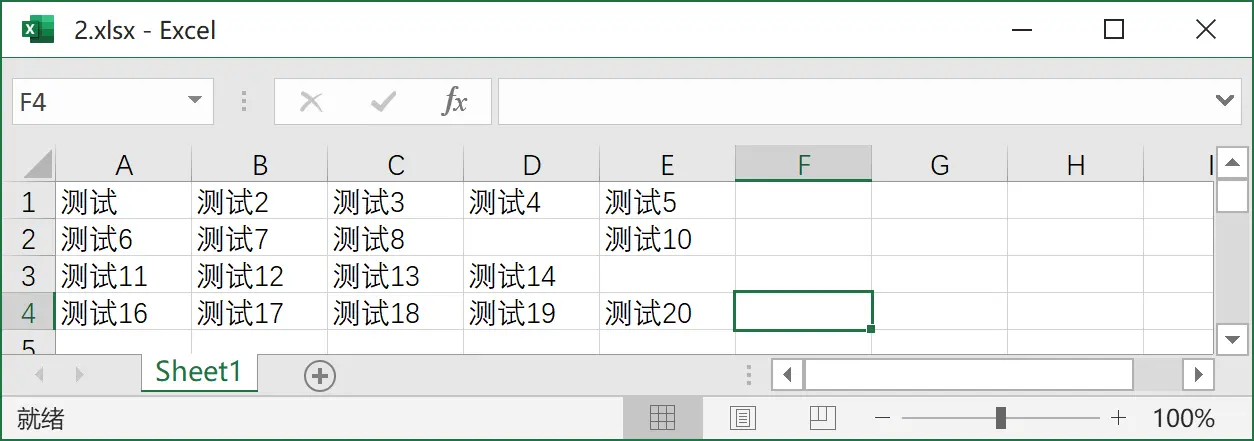
那么,如果你通过上述代码获取下图的 Excel 内容,你将会获得一个一维长度为 4 的二维字符串集合。
1 2 3 4 arrayLists.get (0 ).get (1 ); arrayLists.get (1 ).get (3 );
但是,请注意:如果你运行下列代码,Java 虚拟机将会报错。以下代码将产生数组越界的错误。
1 2 arrayLists.get (2 ).get (4 );
因为你需要注意的是,在 Java 中二维数组的每一行的长度不一定完全相同。不像 C 语言一样,你创建一个 int[4][3]二维数组,每一行都有 3 个数字。
1 2 arrayLists.get (2 ).size (); arrayLists.get (0 ).size ();
但是,如果你将 E3 单元格涂上黄色(也就是给这一个单元格的背景设置为黄色,单元格内依旧不填写任何内容),再次运行以上代码,你将发现以下结果。
1 2 3 arrayLists.get (2 ).get (4 ); arrayLists.get (2 ).size ();
不难发现,其实读取 Excel 文件需要注意非常多的问题。一个单元格是否为空,不完全取决于这个单元格是否存在文本内容。每一行读取的长度并不完全相同。
查阅资料发现,读取 Excel 表格一直是一个难题。因为还涉及到单元格内容格式、单元格样式、单元格隐藏、多工作表、单元格内存在复杂 Excel 公式、单元格合并、多版本 Excel 文件格式兼容等问题。
有了以上的铺垫,我们就能顺利地实现从 Excel 文件中导入数据到应用程序中。当然,在解决 Excel 文件的复杂读取后,你还需要对用户提供的数据进行校验。例如,我们的每一个用户具有身份证、职位等信息。那么,导入时,就需要校验 Excel 文件中身份证一列的数据有效性,还要避免用户借助 Excel 批量导入的功能实施越权操作。
这一个功能同样没有借助任何第三方库实现。实现原理可以扩展到任何需要拖拽功能的应用上。
拖拽添加功能演示(拖拽到哪添加到哪)
排序功能演示
先让我们来思考几个问题,你在拖拽的时候发生了什么?拖拽的时候是什么东西在移动?从 A 拖拽到 B 的时候,如何实现数据交换?
不要把问题想复杂了,第一个问题的答案就是发生了鼠标移动的事件。
第二个问题的答案就是鼠标。
那么,在回答第三个问题前,我们先来思考一下鼠标的作用。鼠标,真的只是一个可以供你移动的图标吗?
经过查阅资料,鼠标其实是一个快递员。也就是中间人。也就意味着,鼠标是可以携带信息的。
那么第三个问题不就非常好回答了,在 A 上发生拖拽事件时,把信息传递给鼠标,然后拖拽到 B 处释放时,B 向鼠标索要信息。
借此,我们就能轻松实现拖拽添加的事件。
让我们来总结一下整个原理。
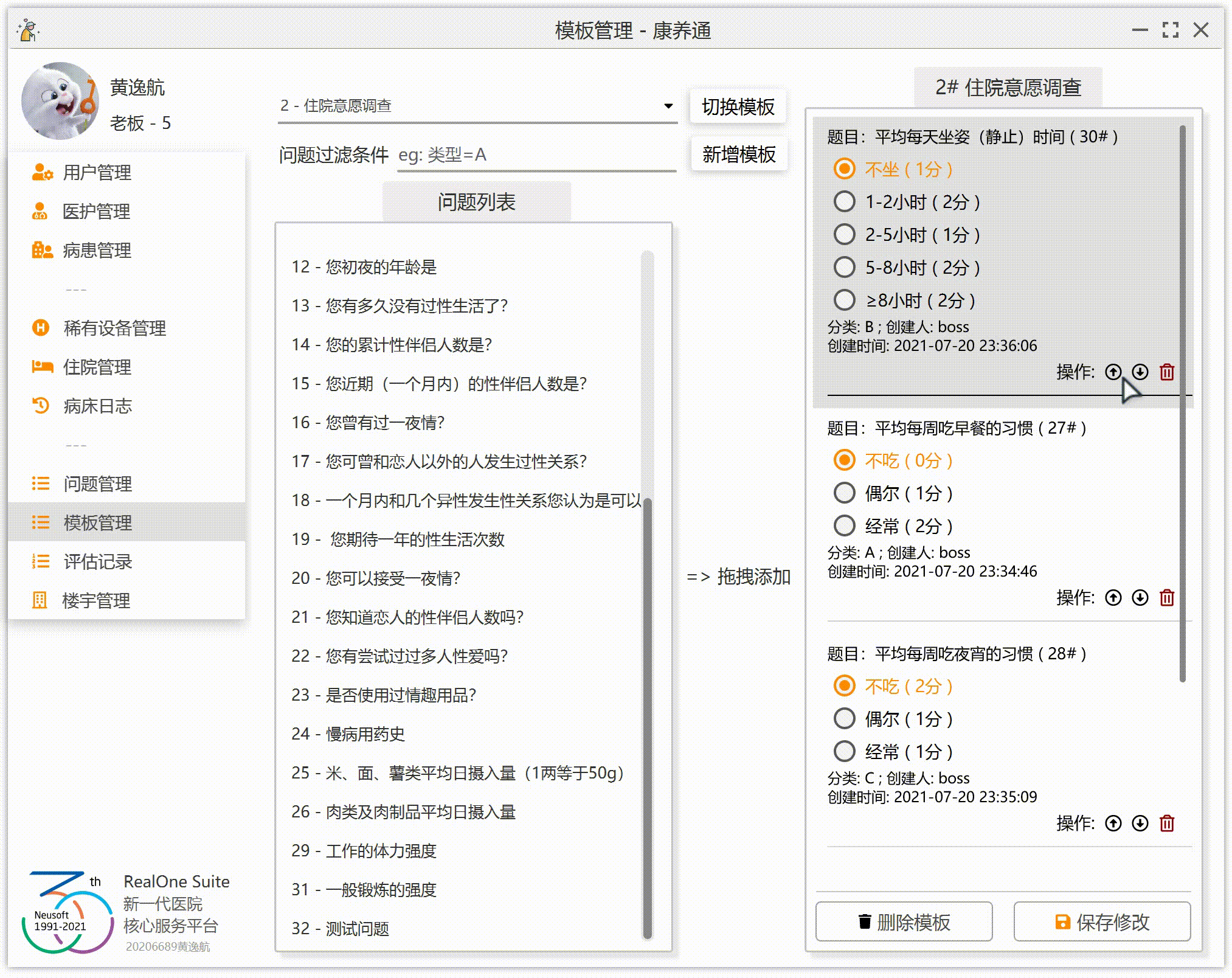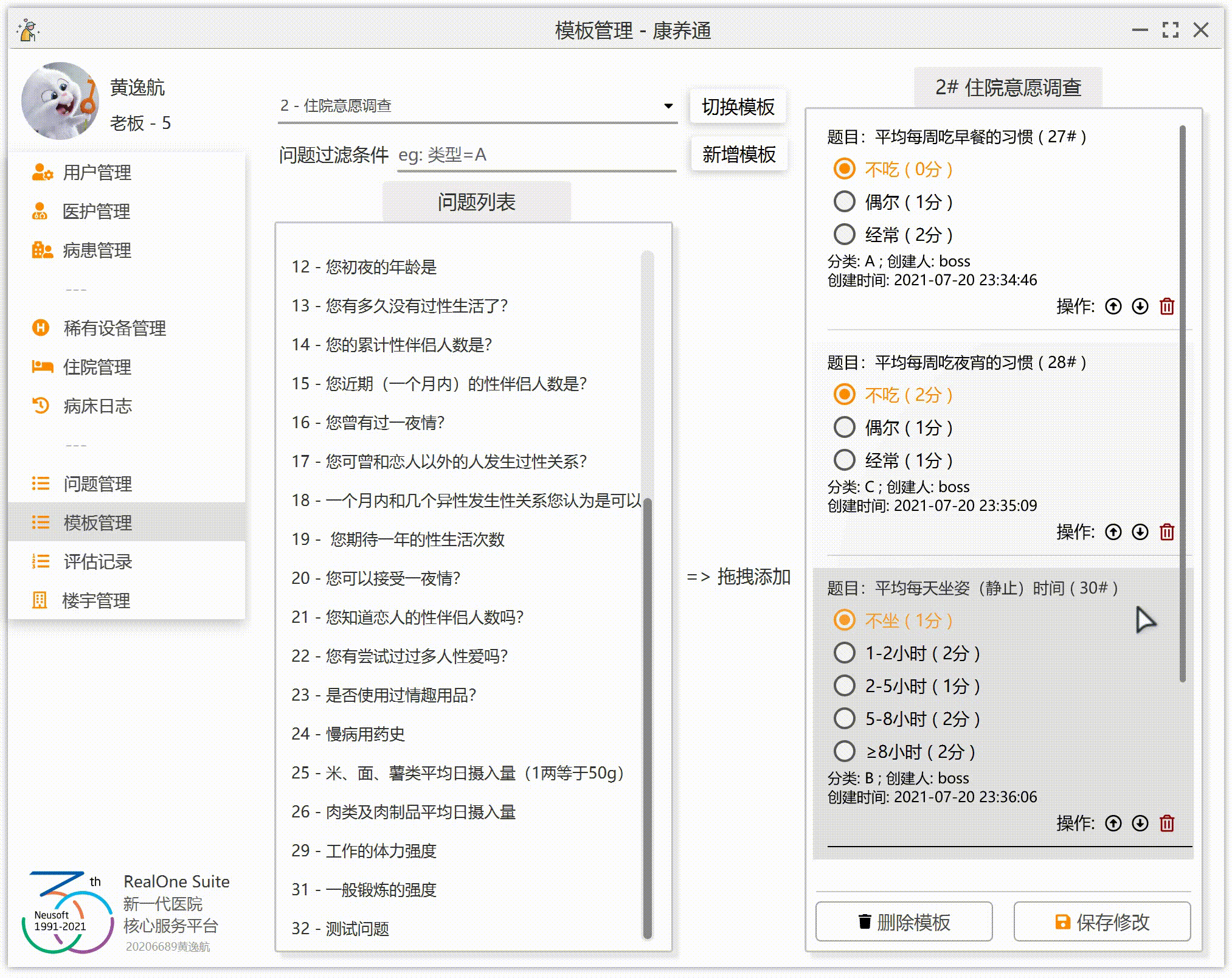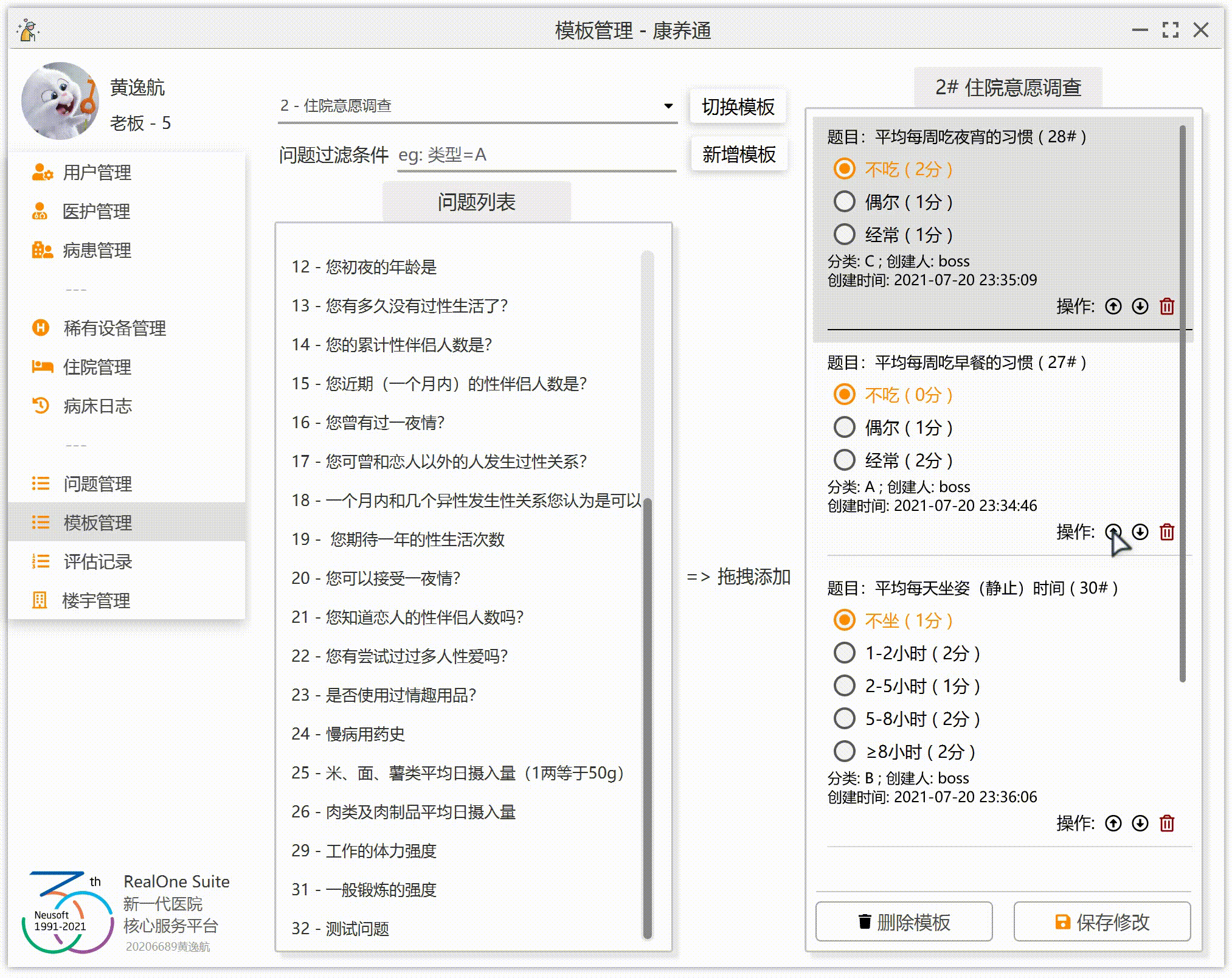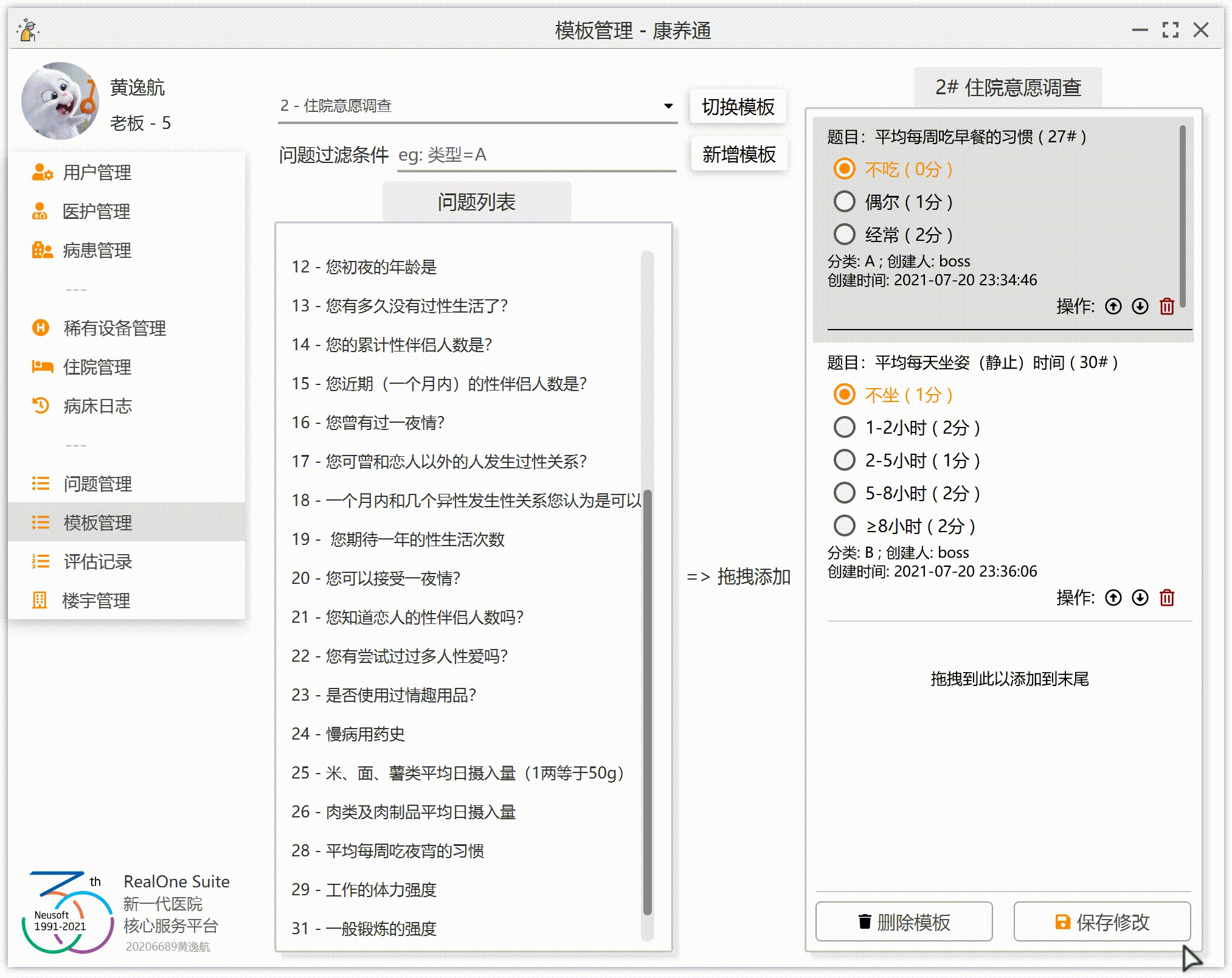
现在我们有左右两个列表。左侧列表 A 是全部问题(除去已经出现在 B 中的问题),右侧列表 B 是当前问卷的问题集合。注意:同一个问题不能同时出现在两个列表中,你不能让同一份问卷被多次添加同一个问题。当用户在左侧列表的某一行上(某一个问题)拖拽时,将这个问题的 ID 赋值给鼠标。当鼠标进入右侧列表,并且释放时,右侧列表向鼠标索要问题的 ID,然后右侧列表根据这一个 ID 在数据库中找到这一个问题,并把这一个问题添加到当前问卷。
难点 1
大致的过程,我们已经了解清楚了。但是,有几个细节我们需要注意。
刚刚我们提到,同一个问题,不能同时出现在两侧列表中。你不能想当然地这样写代码:当一个问题从左侧拖出时,就把这一个问题从左侧列表移除。万一用户只从左侧拖出,但是没有拖入到指定的位置(也就是右侧列表中的任何一个问题上)呢?显然,从左侧拖出,不代表着已经被拖入到右侧列表了。所以,这里需要检测用户是否已经拖入到右侧并且释放。
难点 2:拖到哪添加到哪
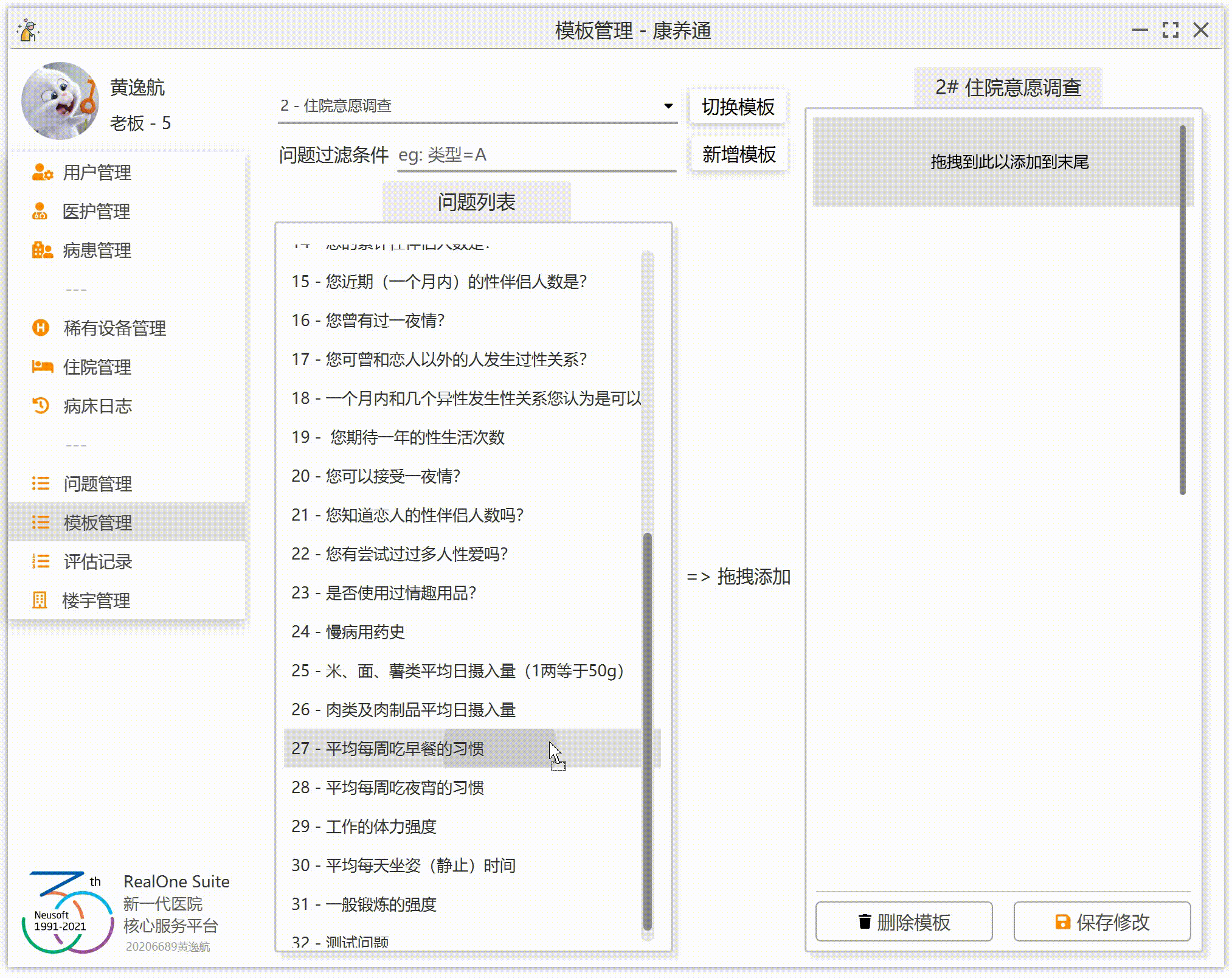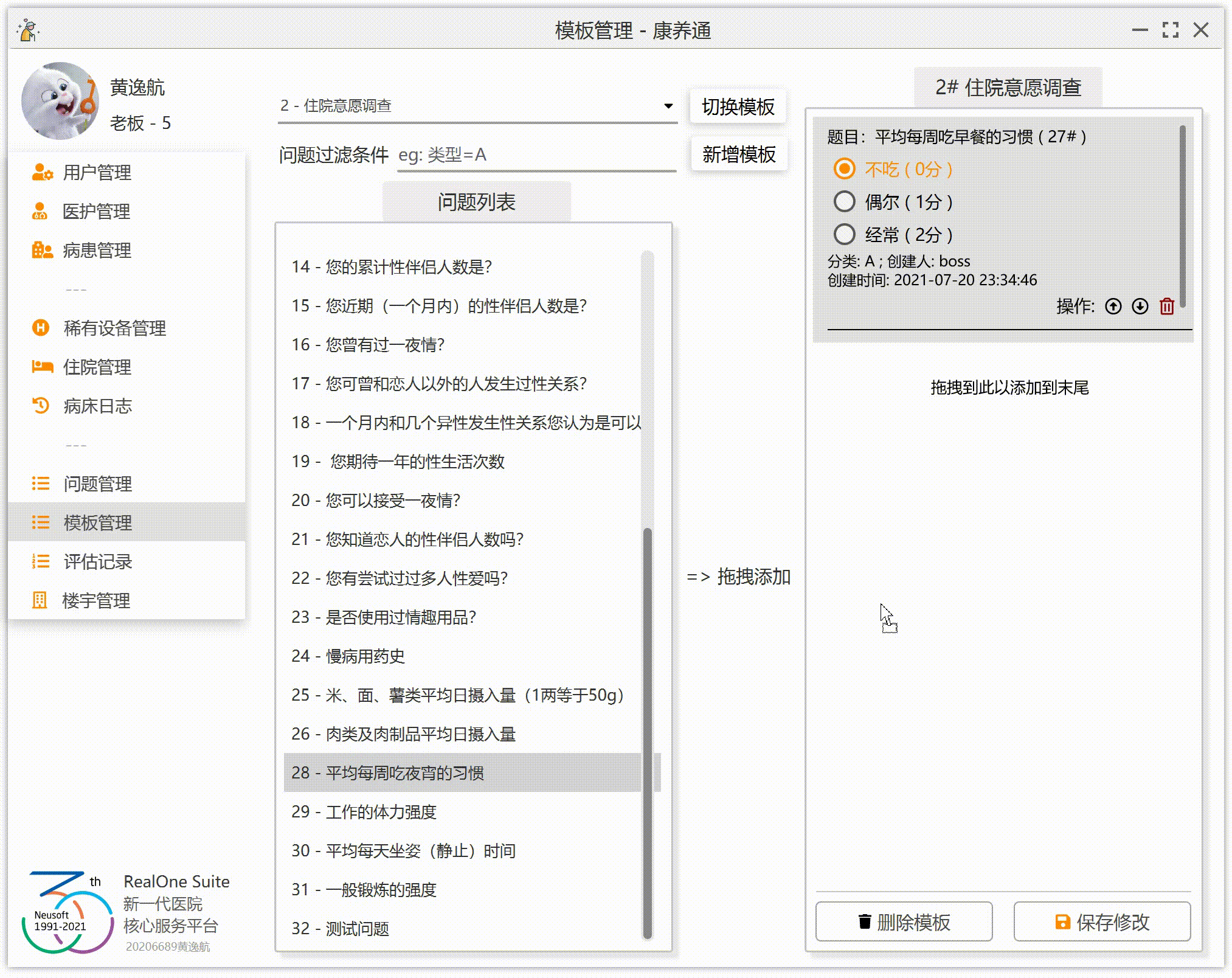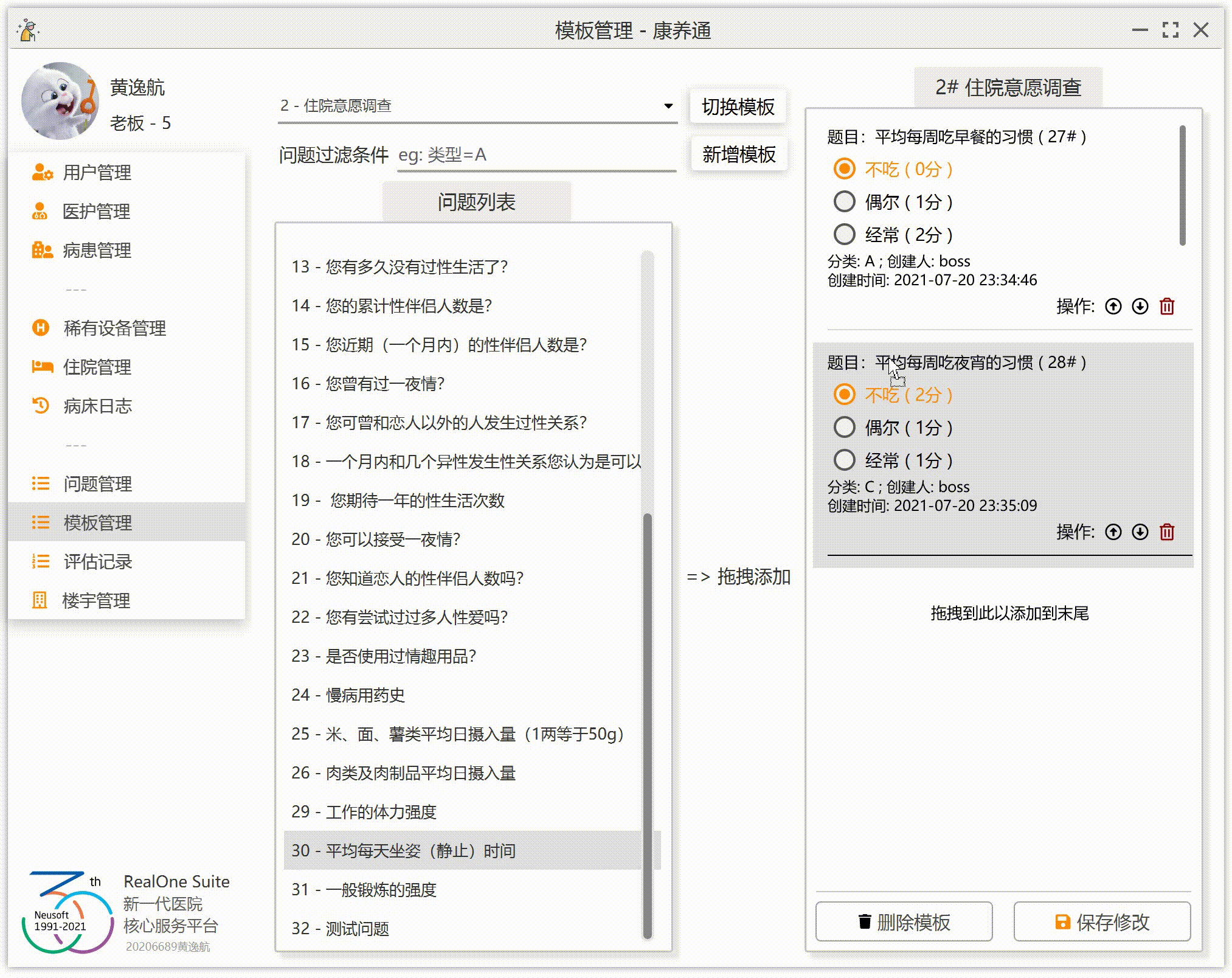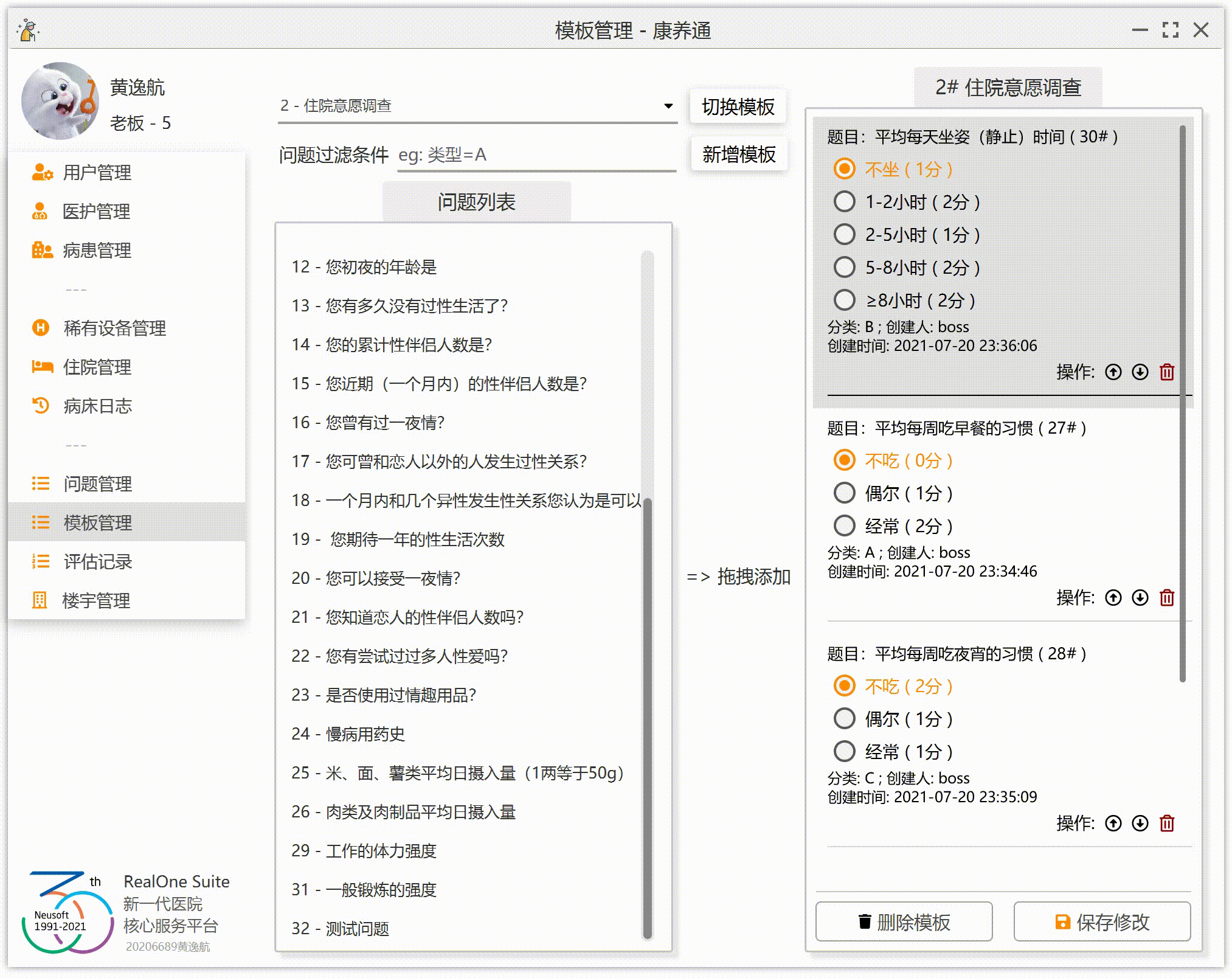
为了让效果更加完美,我们要实现:拖到哪添加到哪(假设右侧已经有 3 个问题 A、B、C,如果这个时候拖入问题 D 到 B 上,那么右侧的顺序应该为 A、D、B、C;如果拖入 D 到 A 上,那么右侧的顺序为 D、A、B、C;如果拖拽到末尾的空白处,那么右侧的顺序应该为 A、B、C、D)。
那么,想要实现上述功能,逻辑应该是这样的:
1.左侧列表监听到拖拽事件,把被拖拽的问题的 ID 赋值给鼠标
2.右侧列表中的某个问题监听到拖拽进入事件,保存当前鼠标的位置。(注意,这里不是右侧列表监听到拖拽进入事件)
3.右侧列表监听到拖拽释放事件,获取鼠标的问题 ID,获取鼠标的位置(这里的位置不是鼠标的 XY 坐标,是步骤 2 中保存的列表位置),然后将这一个问题添加到列表的指定位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vBox.setOnDragEntered(event -> { System.out .println("右侧元素监听到了鼠标拖拽进入事件" ); rightListHoverQuestionID = Integer.parseInt(vBox.getId().split(" - " )[1 ]); int nowPosition = -1 ; int _c = -1 ; for (VBox vBox2 : rightList.getItems()) { _c++; if (vBox.getId().split(" - " )[1 ].equals (vBox2.getId().split(" - " )[1 ])) { nowPosition = _c; break ; } } rightList.getSelectionModel().select (nowPosition); });
难点 3:右侧列表的上下排序
JavaFX 的 ListView 组件并不提供交换两行的函数。那么,我们就需要自己实现。实现的时候,注意极端情况。因为我们在右侧的列表中添加了一个空行(也就是最后一行“拖拽到此处添加到末尾”),我们还需要注意右侧列表的实际问题数量其实是右侧列表的行数量-1。极端情况也不多,只有一个问题的时候,移动是无效的;一个问题在最下面,那么向下移动是无效的。同理,一个问题在最上面,那么向上移动是无效的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 private void rightListUpDownQuestion (String questionID, int operation ) if (rightList.getItems().size() <= 2 ) { return ; } int nowPosition = -1 ; int _c = -1 ; for (VBox vBox : rightList.getItems()) { _c++; if (vBox.getId().split(" - " )[1 ].equals (questionID)) { nowPosition = _c; break ; } } if (operation == 1 && nowPosition == 0 ) { return ; } if (operation == -1 && nowPosition == rightList.getItems().size() - 2 ) { return ; } ObservableList<VBox> observableList = FXCollections.observableArrayList(); for (int i = 0 ; i < rightList.getItems().size(); i++) { if (i == nowPosition + (operation == -1 ? 0 : -1 )) { observableList.add (rightList.getItems().get (i + 1 )); observableList.add (rightList.getItems().get (i)); i++; } else { observableList.add (rightList.getItems().get (i)); } } rightList.setItems(observableList); }
其实,实现这个功能并不复杂。主要的难点在于:如何快速地实现数据交换、理解各种复杂的拖拽事件。
值得一提的是,实现这个功能的时候,不要把两个列表视作一个整体。左侧列表只负责响应开始拖拽事件。右侧列表只负责响应拖拽释放事件。右侧列表的每一行只负责响应拖拽进入事件。他们之间的关联只在于,同一个问题不能同时出现在两个列表中。
其实进一步思考,你能体会到操作系统设计的巧妙之处。鼠标不仅仅是鼠标。
此功能的实现灵感来自陆陆同学。
那一天,陆陆问我:我能不能把整一个 AnchorPane 存到 JSON 中,这样我不就实现了还原用户操作的功能吗?
显然,AnchorPane 是不能存到 JSON 中,因为界面是 JavaFX 渲染出来的,用户的操作是虚拟的,获取 AnchorPane 只能保存布局,而不能保存用户的操作。
但是,如果我们利用节点的截图功能,那我们就能保存用户操作时所看到的界面。
对节点截图非常简单,只需要通过以下的代码。
1 2 3 4 5 6 7 8 9 10 SnapshotParameters params = new SnapshotParameters(); params.setFill(Color.TRANSPARENT); WritableImage image = node.snapshot(params, null ); File file = new File (System.getProperty("user.dir" ) + File .separator + "node.png" );try { ImageIO.write (SwingFXUtils.fromFXImage(image, null ), "png" , file ); } catch (IOException e) { e.printStackTrace(); } System.out.println ("生成快照完成,图片路径:" + file .getAbsolutePath());
显然,这个功能的实现不会这么简单。
因为,我们显示问卷评估界面的时候,是将所有问题放到一个 ScorePane 里面。这样,当问题过多的时候,会显示滚动条。但是,这也带来一个问题,如果我们想要对整个问卷进行截图,我们只能对 ScorePane 进行截图。但是,JavaFX 的截图特性是,只能截取已经显示的部分。也就是,在对 ScorePane 这一类可以滚动的面板进行截图时,是不会截取到没有滚动到的部分的。
说白了,我们要对 ScorePane 实现长截图的功能(和手机的长截图功能相似)。
既然是实现长截图功能,我们就借鉴手机实现长截图的思路(即:先截取一部分,然后滚动到下一部分,然后再截取,然后拼接全部的部分)。
但是,直接套用这个思路到 JavaFX 上会发现,获取 ScorePane 的现有位置并进行滚动,是一件困难的事情。因为你还要考虑到一个问题,假如 ScorePane 的内容高度为 600 像素,ScorePane 的显示高度为 400 像素,也就是有 200 像素需要通过滚动才能看到。如果你先对 ScorePane 的最上面 400 像素进行截图,然后再滚动到最下方进行截图,你会发现中间有 200 像素的内容是重复的。这意味着,你在合并截图时非常困难。据我所知,JavaFX 只能对一个节点进行完整截图,而不能选取一个节点的部分区域进行截图。
难道,我们就要放弃这种思路了吗?
不,我们把长截图的思路稍作转换。我们的 ScorePane 的子节点是一个个问题。如果我们对每一个问题节点进行截图,然后进行拼接,就完成了长截图的操作。这种转换后的思路,显然更加快捷且是有效的。
这里我们需要借助到工具类以实现图像拼接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package com.pension.utils.image;import java.awt.image.BufferedImage;import java.io.IOException;public class MergeImageUtil { public static BufferedImage mergeImage (BufferedImage img1, BufferedImage img2, boolean isHorizontal) throws IOException { int w1 = img1.getWidth(); int h1 = img1.getHeight(); int w2 = img2.getWidth(); int h2 = img2.getHeight(); int [] ImageArrayOne = new int [w1 * h1]; ImageArrayOne = img1.getRGB(0 , 0 , w1, h1, ImageArrayOne, 0 , w1); int [] ImageArrayTwo = new int [w2 * h2]; ImageArrayTwo = img2.getRGB(0 , 0 , w2, h2, ImageArrayTwo, 0 , w2); BufferedImage DestImage = null ; if (isHorizontal) { DestImage = new BufferedImage (w1+w2, h1, BufferedImage.TYPE_INT_RGB); DestImage.setRGB(0 , 0 , w1, h1, ImageArrayOne, 0 , w1); DestImage.setRGB(w1, 0 , w2, h2, ImageArrayTwo, 0 , w2); } else { DestImage = new BufferedImage (w1, h1 + h2, BufferedImage.TYPE_INT_RGB); DestImage.setRGB(0 , 0 , w1, h1, ImageArrayOne, 0 , w1); DestImage.setRGB(0 , h1, w2, h2, ImageArrayTwo, 0 , w2); } return DestImage; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 bufferedImage = null ; for ( int i = 0 ; i < vBoxMFXListView.getItems().size(); i++ ){ SnapshotParameters params = new SnapshotParameters(); params .setFill( Color.WHITE ); WritableImage image = vBoxMFXListView.getItems().get ( i ).snapshot( params , null ); if ( bufferedImage == null ) { bufferedImage = SwingFXUtils.fromFXImage( image, null ); } else { try { bufferedImage = MergeImageUtil.mergeImage( bufferedImage, SwingFXUtils.fromFXImage( image, null ), false ); } catch ( IOException e ) { e.printStackTrace(); } } }
其他界面因为只是 JavaFX 基础组件的运用,以及一些基础功能的实现,这里就不再做赘述了。
因为第一次使用 Java 语言制作应用程序,在数据结构的设计方面不大理想,尽管后期进行了一定的修改和弥补,但还是有相当一部分的结构不是最优的。经过此次的实训,我发现我在软件架构和数据结构设计方面有所欠缺。
在设计方面,经过一系列客观评价,总体设计处在能看能用的水平。上次假期阅读的《写给大家看的设计书》也派上了用场。
Java 方面,加深了一些概念的理解。不难发现,程序中涉及到大量的单元格渲染,这导致整个应用程序的首次响应时间非常长。我尝试着使用多线程、节点缓存等方法进行优化,但效果非常不理想。很遗憾,这次没用上 Maven 来构建项目。
实训有收获了不少,学会如何整理需求文档,预先安排好项目结构,做好一定的项目规划,试着开发更加先进且实用的功能。尝试从零实现一个功能,能学习到非常多方面的知识。
虽然这是一次实训任务,但就像我开发墨灵一样,把一个应用程序设计成“可用、实用、易用”而不仅仅是“能用”。
本次项目基于 JDK16,JavaFX SDK11。因为与大多数同学的环境不同,故源代码就不再整理开源了(本项目依赖了超过 15 个库,因为第一次开发 Java 项目,还没熟悉 Maven,所以开源也非常麻烦)。
如果你想要高效地完成实训任务,建议你采取以下步骤:
电脑配置好 JDK 16+
下载 Scene Builder 11
下载并安装 IDEA、配置 JDK16、下载并配置 JavaFX SDK11
充分使用 JFoenix 等第三方库
完成需求书,而不是完成任务书。做好界面,而不是让实践报告看上去又臭又长。
准备好风扇以及网络通讯设备。
时刻做好答辩准备。
从第一天开始做,而不是从第三周开始做。